
出于数据安全的考虑,我们项目中的Redis集群是自己部署的,未使用云服务。有天运维突然打来电话,线上redis挂了,重启了也不行。心想不可能,高可用架构怎么会出错?
背景
我使用三台服务器部署了redis的cluster三主三从集群。为避免单点故障,采用交叉部署,如下图所示
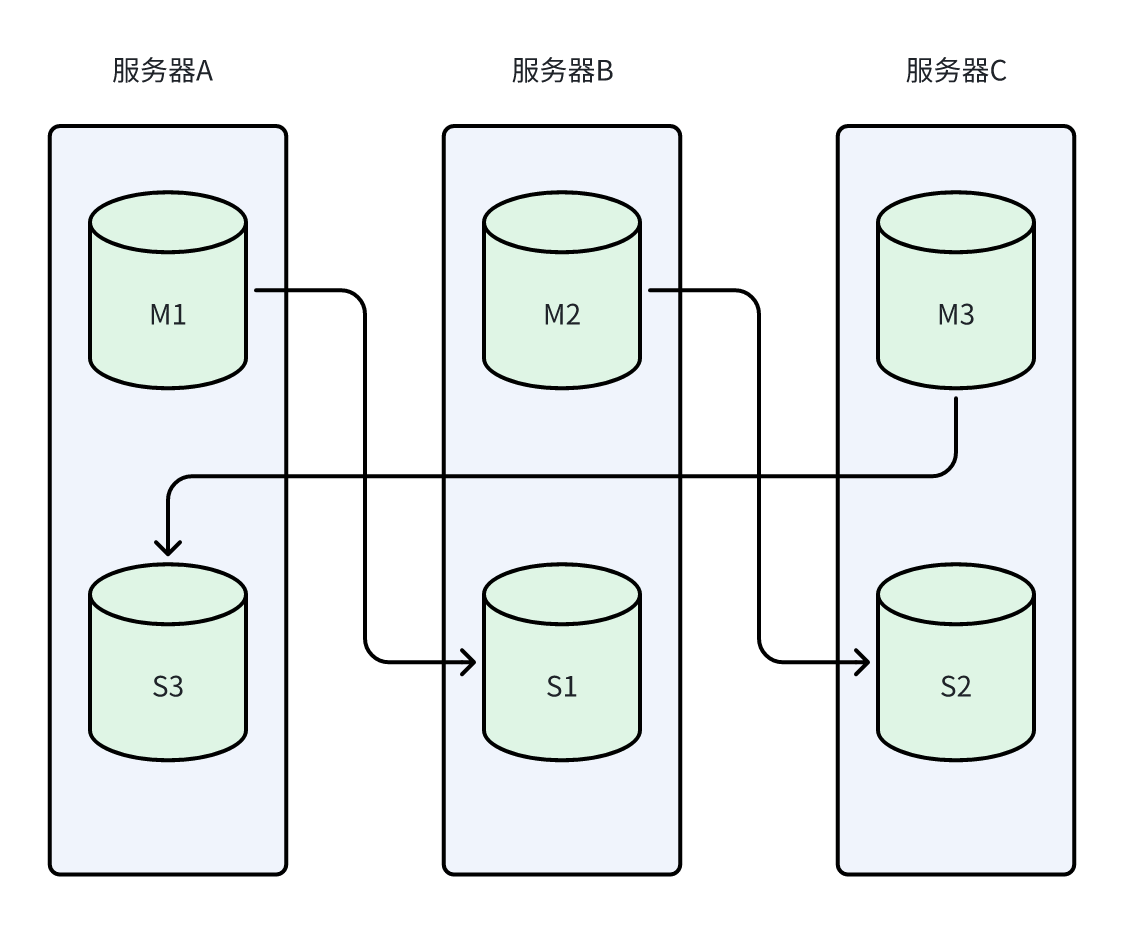
问题
排查发现,原因是这样:
服务器B出现网络故障,M2无法回应其它节点的问询被判定下线,S2发起选举。由于M2只有一个从节点,因此S2顺利被选举为新的主节点,集群可用
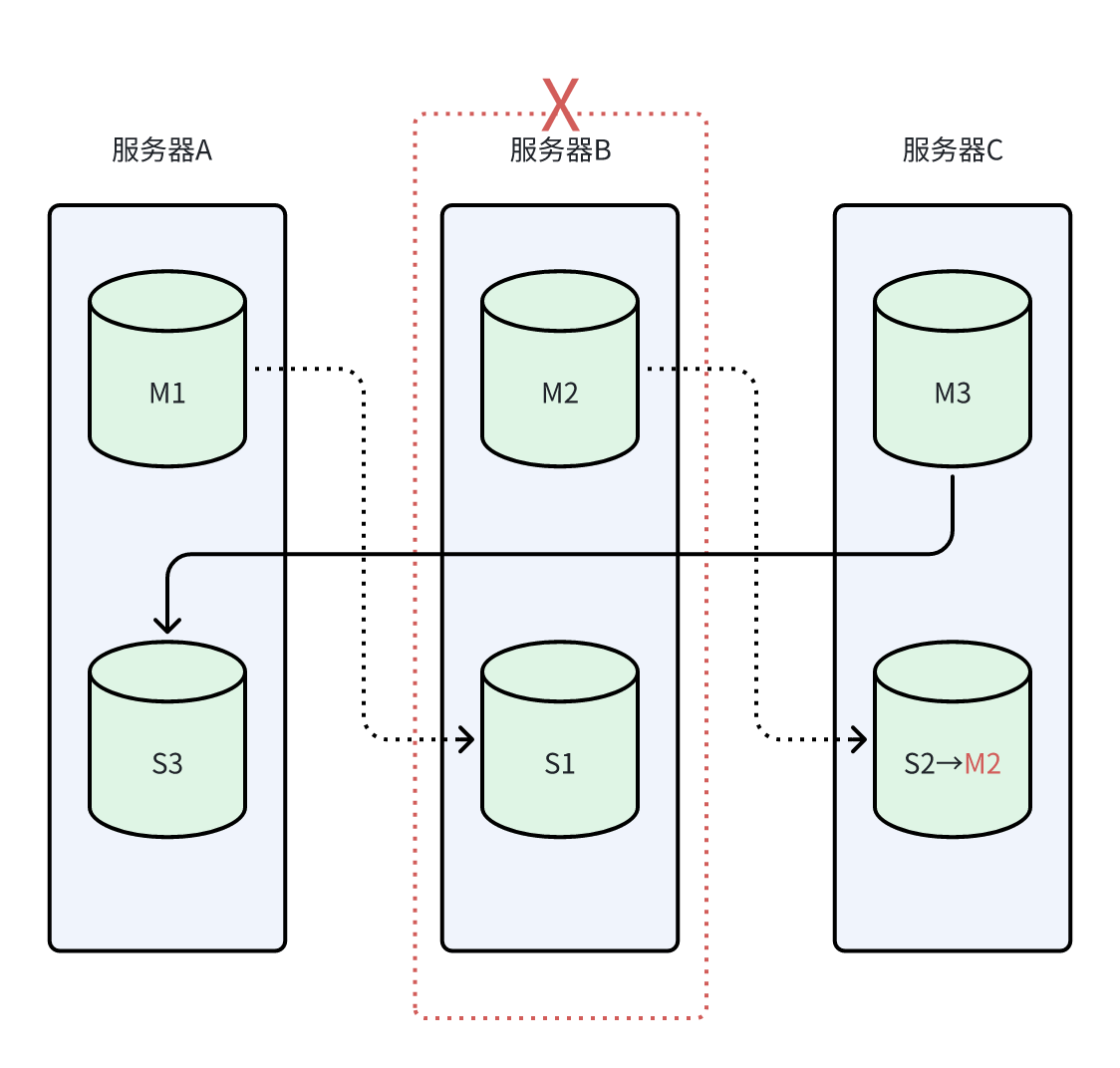
之后服务器B恢复,发现已有新的M2,老的M2会自动降级为从节点,向新M2请求复制,如下
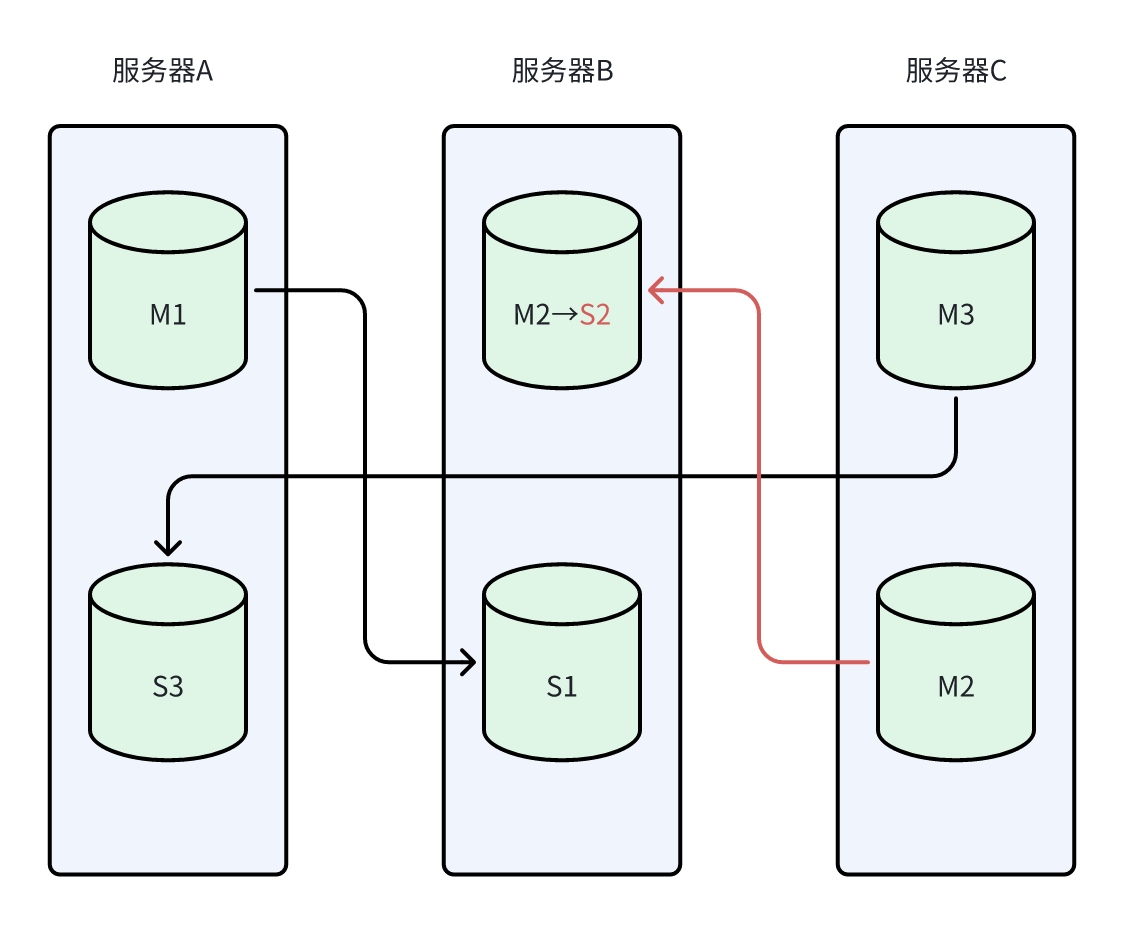
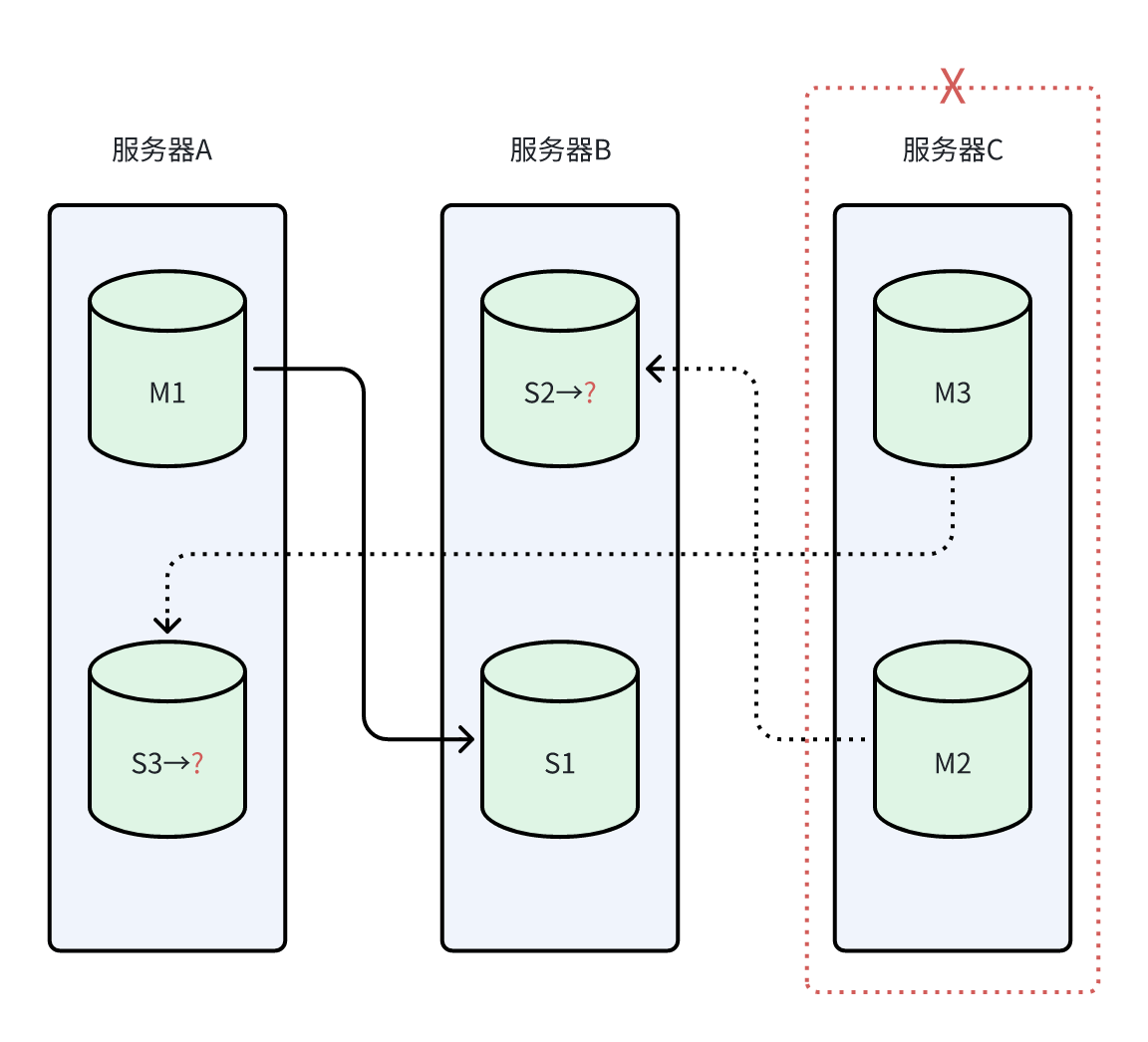
由于此过程集群一直是可用的,运维人员在恢复服务器B后就未再做任何操作。但M2和M3已经集中到了服务器C上。如果下一次是服务器C出现故障,主机将只剩下M1。即使S2和S3发起选举,但由于此时存活的主节点不足1/2,选举无法完成,导致集群不可用。
解决方案
-
在保持3台机器不变的情况下,应该在第一次故障转移后,手动恢复集群交叉部署状态。
在S2上执行
CLUSTER FAILOVER命令,使M2和S2主从关系调换CLUSTER FAILOVER会按以下步骤执行:
- 需要主节点在线并能响应
- 从节点会请求主节点停止处理客户端请求
- 主节点确认所有写入操作已同步到从节点
- 然后执行角色切换
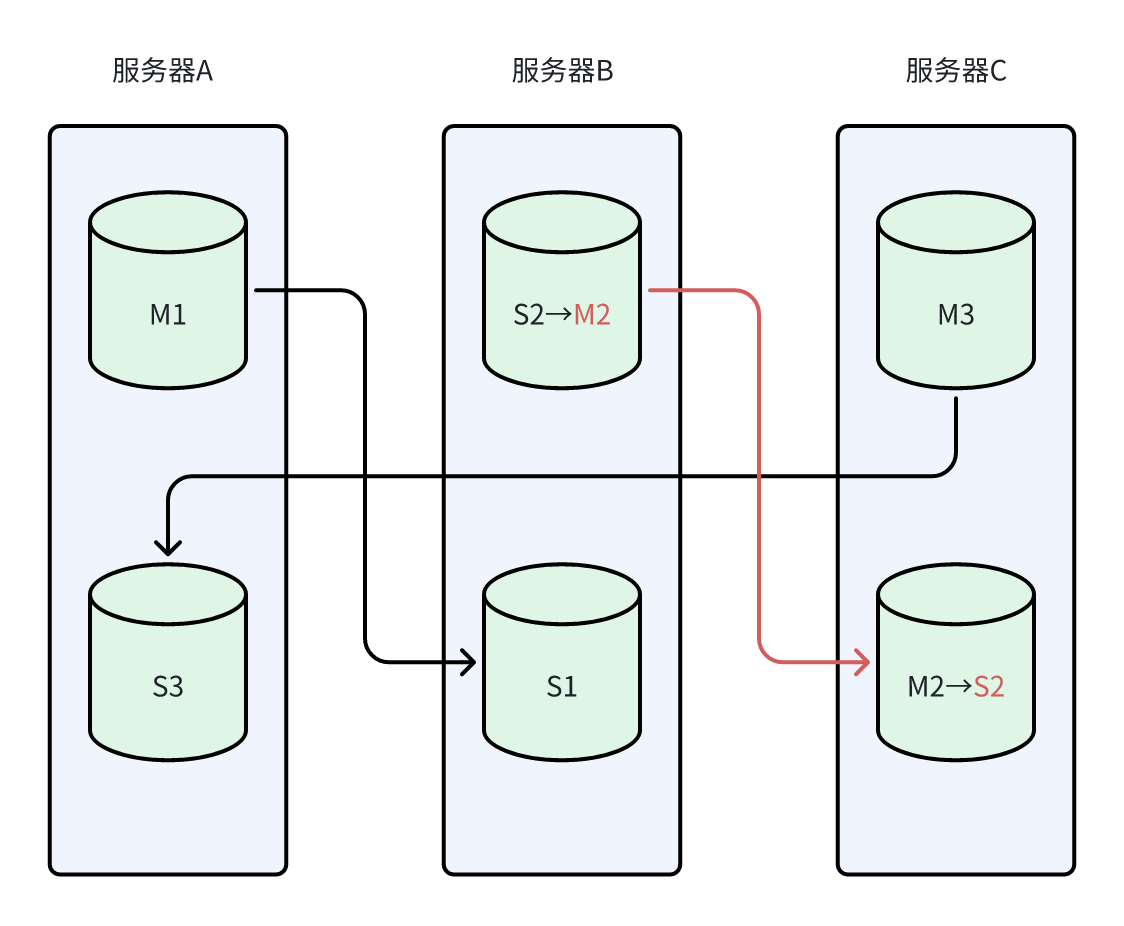
-
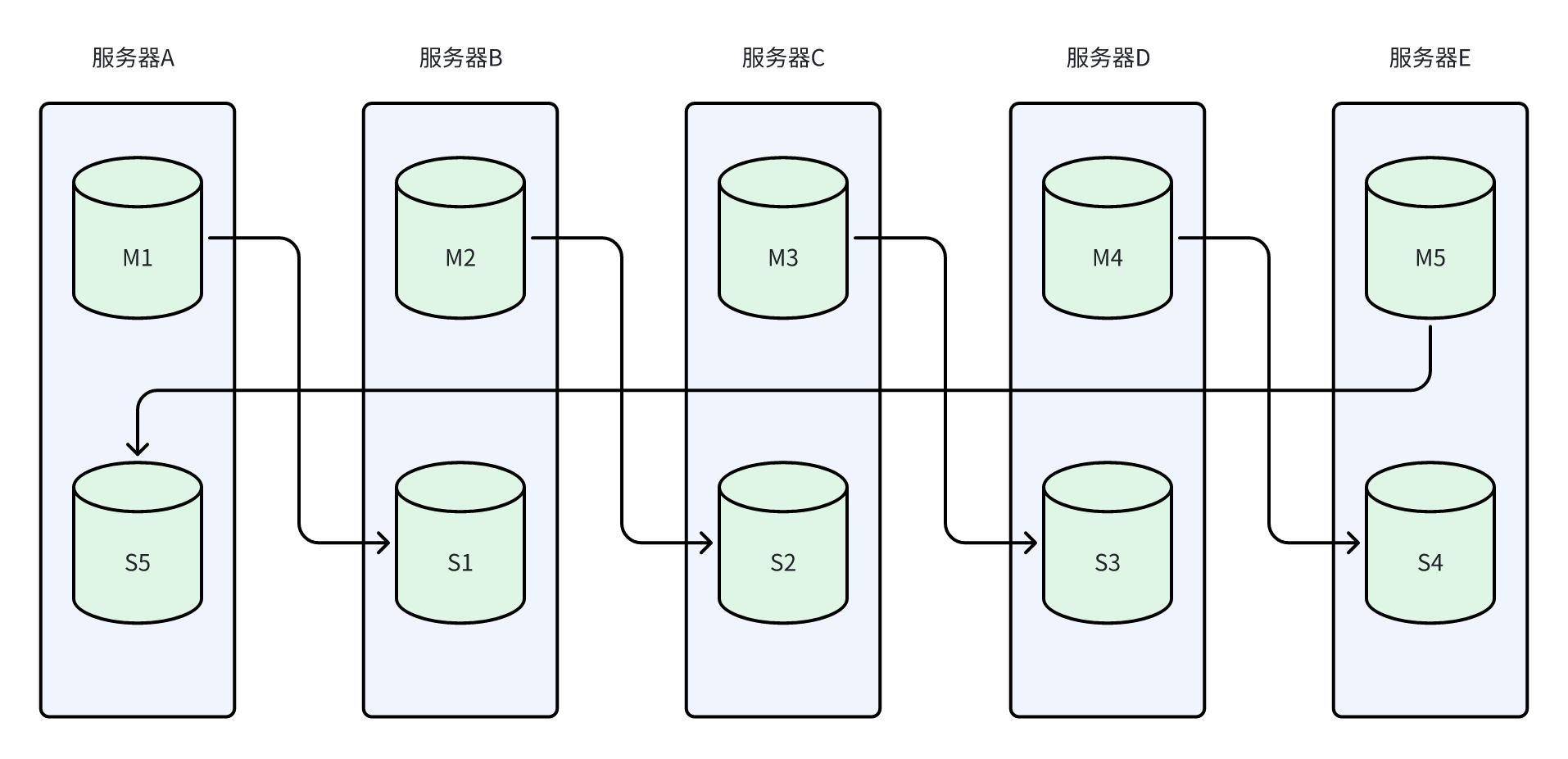
使用5主5从的集群,这样即使出现2台主节点同时下线的情况,依然有3台主节点存在,不会影响后续的选举。
- 故障前,5主5从交叉部署架构
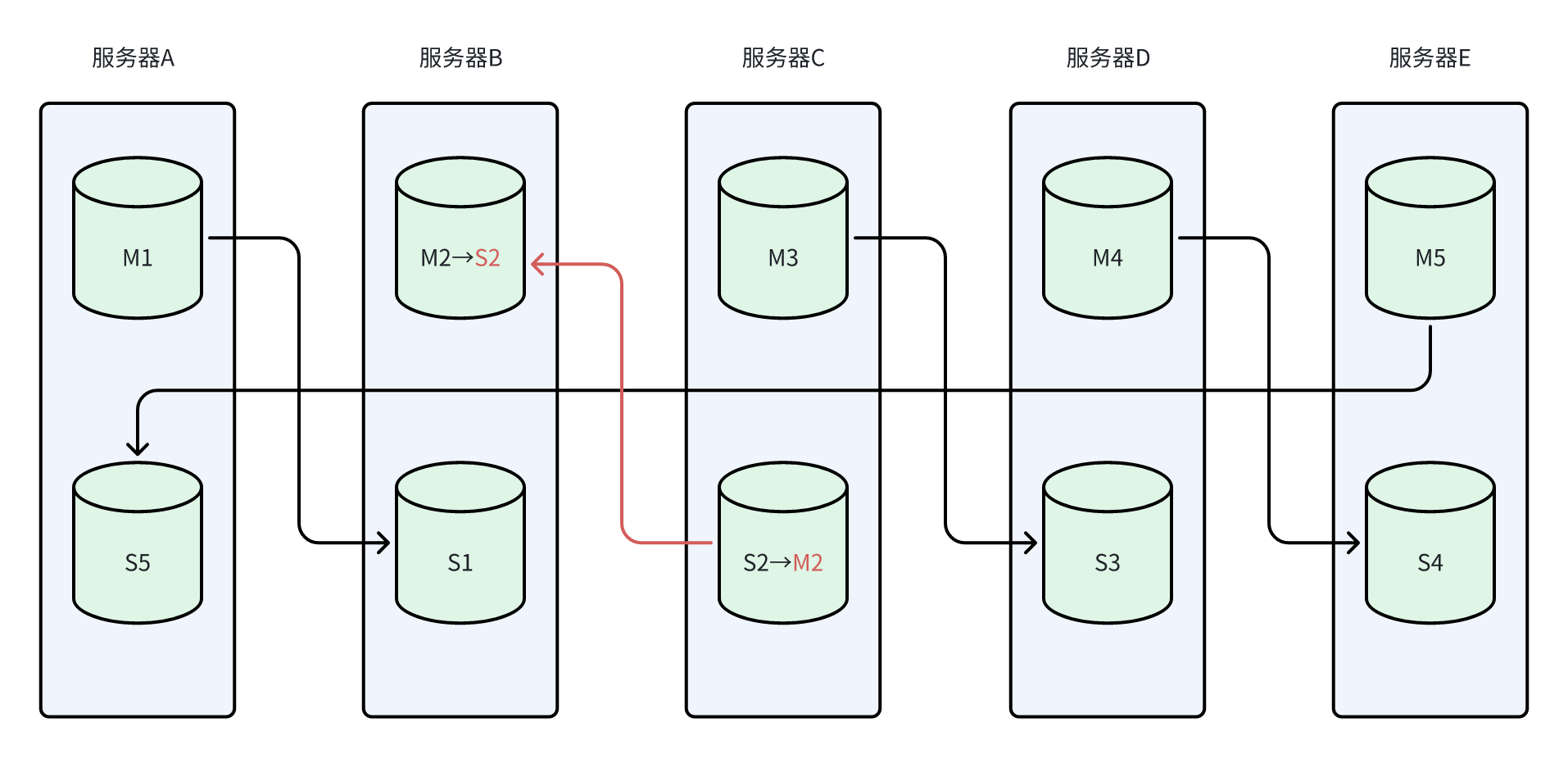
-
服务器B故障恢复后,S2和M2调换位置,M3、M2集中到一台机器上
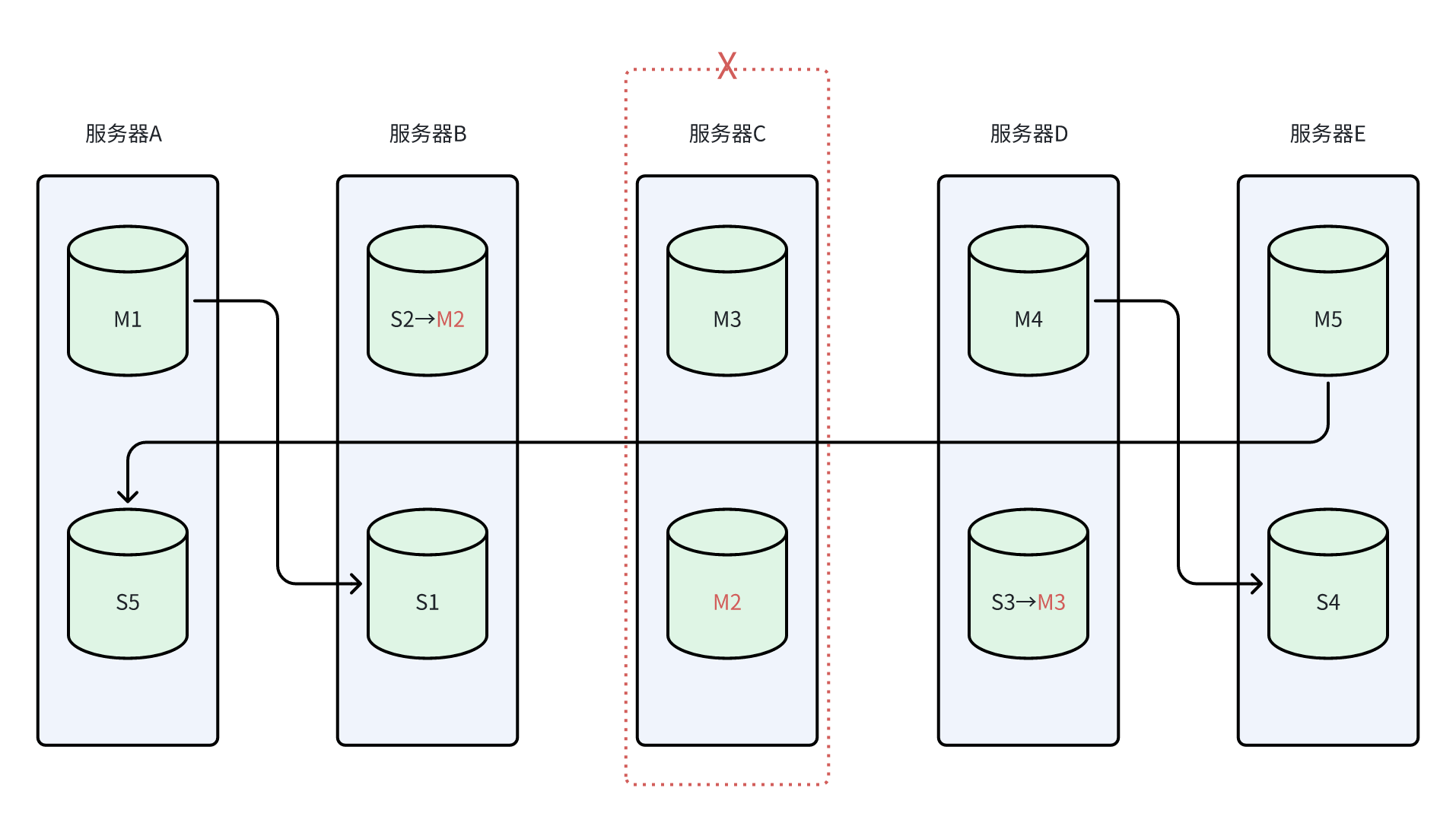
-
服务器C故障后,S2、S3发起选举,M1、M4、M5依然可以投票成功,集群保持高可用


{kind=link}